2025-12-23 00:00
Projetos Inteligência Artificial IA Visão Computacional desnvolvimento
Arctic Skies, aeye, Picsort e um Yak Gigante!
Olá Internet! Estamos a chegar ao fim do ano, e nada melhor que um artigo um pouco mais longo para contar uma história!
Em 2024 mudei-me para o círculo polar ártico, onde auroras boreais são uma visão comum. No entanto, não é algo que olhamos pela janela e, pronto, lá está ela todas as noites. Não, a aurora boreal requer condições especiais, sendo a principal céus limpos. Como tenho mais que fazer na minha vida e gosto de automatizar coisas, a primeira coisa que pensei foi: “Quão fixe seria ter uma câmara na varanda, a fazer stream 24/7 com um modelo de visão computacional a enviar-me notificações quando a aurora está visível?”. E aqui começou a aventura, um projeto que me tem vindo a ocupar algum tempo durante o último ano e que ainda não está completamente terminado!
A parte da stream foi fácil. Embora tenha iterado por várias câmaras e métodos, a arquitetura é simples. Começou com um simples Raspberry Pi e uma webcam na varanda, mas achei que precisava de algo um pouco mais robusto que aguentasse estar mesmo do lado de fora. Como já tinha um router Ubiquiti Dream Machine, acabei por assentar numa pequena Ubiquiti G4 Instant. O ecossistema Unifi torna tudo simples: o Unifi Protect gere a câmara, grava 24/7, publica a stream RTSP, e depois o OBS corre numa máquina que faz a stream para a Twitch e YouTube. Talvez um dia publique um artigo mais técnico sobre isto, mas por enquanto ficamos por aqui!
O passo seguinte, a tosquia do yak, começou! Após algumas horas de pesquisa, rapidamente descobri que não existem modelos de visão computacional para detetar auroras boreais. Logo, tinha de criar um, mas, claramente, não fazia a menor ideia de como o fazer! Qualquer pesquisa que fazia acabava em documentos científicos sobre redes neurais e convolucionais, coisas que ainda hoje não percebo como raio funcionam. Eu só queria mesmo saber como é que se treina um modelo de visão computacional! É aqui que os LLMs se podem tornar muito poderosos e facilitar horas e horas de pesquisa! Após um pouco de chat, entendi que precisava de um dataset com imagens para treinar o modelo, Python, TensorFlow e Keras!
O dataset
Dataset? Fácil! O Arctic Skies já estava a gravar há algum tempo, por isso tinha bastantes timelapses. Fiz o download de todos e rapidamente criei um script para extrair cada frame. Criei outro script para organizar as imagens, bastante simples: iterava por todas as imagens, e eu só tinha que carregar ‘Y’ em cada imagem com aurora e ‘N’ nas imagens sem aurora. Estas imagens eram movidas para o respetivo diretório com o nome ‘1’ e ‘0’.
O primeiro modelo
“Vibe coding” não é muito a minha cena, mas ainda assim fiz o LLM cuspir algum código para treinar o primeiro modelo e para me ajudar a ter uma ideia de como raio isto funciona. No entanto, a este ponto ainda não prestei muita atenção, só queria mesmo ter um script básico que treinasse o modelo com as minhas imagens. Afinal de contas, embora eu não entenda muito bem como funciona, treinar este tipo de modelos é um problema já bem conhecido e resolvido, certo? Quão difícil pode ser? Famosas últimas palavras… Depois disto, com a ajuda de um LLM, consegui criar o primeiro script para treinar o modelo, ainda sem entender muito do que se passava.

Fantástico! O primeiro modelo foi treinado e estava a funcio… oh oh!
Aeye e Inferência
Tenho pena de não ter guardado os resultados dos treinos dos primeiros modelos, mas o que se segue vai provavelmente deixar-vos com uma ideia. Aqui aprendi o significado de “inferência”, e para o efeito nasceu o projeto da primeira side quest: aeye. Os requisitos deste script eram simples: subscrever a stream RTSP publicada pelo Unifi Protect, fazer inferência a um frame por segundo e exportar o resultado de forma a que possa ser utilizado em tempo real. O script está aqui e este manteve-se quase inalterado durante todo o processo. O OpenCV abre a stream e extrai um frame a cada segundo, o TensorFlow carrega o modelo e faz a inferência e, como não podia deixar de ser, os resultados são expostos como métricas Prometheus. Deste modo, posso utilizar o Grafana para observar dados em tempo real, dados históricos e criar alertas!
Não foram precisos muitos dias a correr a inferência para perceber que, apesar de o modelo conseguir identificar auroras óbvias, estava também a identificar nuvens e outros artefactos como auroras! De volta à estaca zero!
Após mais umas linhas de chat e pesquisas, fiquei (mal sabia eu!) convencido de que para resolver o problema tinha de obter mais imagens — vamos considerar que para cada classe seria necessário pelo menos 800 imagens. Assim que olhei para a quantidade de imagens que tinha de organizar, até fiquei maldisposto!
Mudar o script que utilizei anteriormente para separar imagens por classe não era de todo uma opção viável. O script trabalha diretamente no sistema de ficheiros, começa na primeira imagem e acaba na última, não permitindo voltar atrás nem alterar decisões erradas. Como utilizador ávido de Neovim, a utilização repetitiva do rato para tarefas de produtividade repugna-me, logo a ideia de utilizar um explorador de ficheiros para esta tarefa caiu por terra! Darktable? Quase que levou a taça, mas está tão focado em fotografia que marcar imagens e filtrar não era bem intuitivo e utiliza um sistema de metadados próprio! Após alguma pesquisa, encontrei outras ferramentas, umas open-source, outras proprietárias. Umas prometiam ser extremamente rápidas, no entanto, assim que tentava carregar as mais de 1000 imagens, parecia que voltava à idade da pedra. Outras nada claras nem intuitivas. Nada parecia servir o propósito, e a semente começou a brotar: a ideia de criar uma aplicação para o efeito começou a tomar forma!
Será assim tão complicado?
Depois de tanta frustração a tentar aplicações e ferramentas diferentes, a derradeira frase começou a repetir-se vezes e vezes sem conta na minha cabeça:
“Eu não sou programador de raiz, mas já estou confortável com Go. Não deve ser assim tão difícil criar uma aplicação que faça exatamente o que preciso!”
Como queria aprender um pouco mais sobre desenvolvimento web, decidi que ia desenvolver o conceito como uma aplicação web, mesmo sabendo que este não seria o formato ideal para este tipo de projeto e que mais tarde o iria deitar fora. O objetivo principal era apenas um: ajudar-me a entender melhor a minha ideia, perceber exatamente o que quero e o que preciso e, no processo, aprender algo novo! Decidir o stack foi fácil: um monolito com Go, HTMX e JavaScript. Simples? Pois claro… não demorou muito até as dores de cabeça começarem a aparecer. Como não podia deixar de ser, decidi testar o hype à volta dos LLMs. Todos os dias alguém escrevia no X ou fazia um vídeo no YouTube sobre como utilizaram um LLM para, só com uma simples prompt, gerar uma aplicação que os fez ricos! Se um LLM consegue fazer tal coisa, então se calhar também consegue fazer a minha aplicação simples, certo? Vamos ficar só por aqui… não, os LLMs não vão substituir os programadores tão cedo!
Desde typos a esquecerem-se de metade da tarefa, não havia ameaças sobre a avozinha ter um ataque cardíaco ou orbes do caos que chegassem para conseguir obter uma aplicação funcional! Não quero com isto dizer que a utilização de LLMs não foi útil! De facto, sem eles não teria sido tão rápido nem aprendido tanto. No entanto, a abordagem tinha que mudar! Como aquilo que sei menos é frontend, comecei por aí e fui pedindo para desenhar cada parte da UI em isolado. Primeiro, o contentor para a aplicação toda, depois o contentor para a pré-visualização, depois as miniaturas… e por aí fui, a desconstruir o problema em vários problemas mais pequenos, com o devido contexto, utilizando o LLM como um assistente e um tutor em vez de um programador! Não é objetivo deste artigo ir muito a fundo no que foi feito, mas após várias iterações, entre frontend e backend, o protótipo da aplicação estava feito. Era possível fazer upload de imagens, movê-las entre os vários contentores, exportar… tudo isto apenas com o teclado e com navegação ao estilo do editor de texto VIM! O resultado final está disponível aqui: https://picsort.coolapso.sh, mas é bem possível que venha a ser retirado, pois a aplicação não é de todo viável: trabalha diretamente no sistema de ficheiros, não há qualquer tipo de caching e, obviamente, estou a limitar a sua utilização a cerca de 100 imagens, para não falar que levanta sérias questões de privacidade, visto que não há qualquer tipo de encriptação!
Obviamente que esta brincadeira custou tempo, que nesta altura se encontrava dividido entre várias outras coisas, o que tornou a coisa ainda mais complicada. Estamos a falar de que já se tinha passado pouco mais de um ano desde que comecei, e ainda não tinha um modelo de visão computacional pronto para quando chegasse o inverno e a época das auroras boreais! Felizmente, tive oportunidade de reorganizar as minhas prioridades e passei a poder dedicar mais tempo a este projeto. Uma vez que já sabia melhor o que queria, foi altura de começar a desenvolver a versão desktop de Picsort e finalmente conseguir organizar as imagens do dataset. Obviamente que esta parte do projeto não veio sem a sua dose de dores de cabeça e missões secundárias.
Para desenvolver a versão desktop de Picsort, decidi, como é óbvio, utilizar Golang e o Fyne toolkit. E porque decidi que as imagens originais são sagradas e que a aplicação não deve operar diretamente nos ficheiros, optei por SQLite — até porque mais tarde talvez seja útil poder ter a mesma imagem em várias classes!
A parte mais difícil foi entender como utilizar o Fyne para desenhar a aplicação. É um campo completamente novo para mim e, depois de várias horas (talvez dias) a brigar com LLMs e as suas alucinações, comecei a entender melhor como criar aplicações com Fyne. Foi só mais tarde, quando me juntei ao Discord dos desenvolvedores do Fyne e comecei a falar sobre o que estava a tentar fazer, que realmente entendi algumas das opiniões do Fyne e que, de facto, estava a tentar fazer algo para o qual esta biblioteca não estava preparada. Isto resultou em várias discussões realmente úteis e educativas e em vários pull requests com bug fixes e novas funcionalidades! Como por exemplo #5961, onde uma nova callback foi adicionada, ou #5996, que corrige um bug na navegação de grelhas, entre outras motivadas por algumas funcionalidades implementadas no Picsort, que à data da escrita deste artigo estão ainda para ser aprovadas! Funcionalidades estas que foram implementadas após finalizar a aplicação e começar a utilizá-la para organizar as imagens, pois percebi que algumas das ideias anteriores não funcionavam bem ou que estava constantemente a sentir falta de alguns atalhos de navegação!
É desta! Ou talvez não…
Com o Picsort terminado e as primeiras versões disponíveis, agora tinha o meu dataset organizado e pronto para treinar a nova versão do modelo! Com o script aeye já pronto para treinar modelos com multi-classes, estava cheio de confiança que ia ser desta. Mas ainda não! Depois de treinar, o modelo acabou com cerca de 30% de exatidão, o que significa que passa a maior parte do tempo a “adivinhar” o que está a ver! Foi aqui que entendi a importância de dividir as imagens em 3 datasets: 60% dos dados para treino, 20% para validação e outros 20% para o teste final. Para isto, tive que desenvolver mais algumas funcionalidades para o Picsort, para que esta separação fosse feita de forma automática e adequada! Mas com estes novos números, significa que agora tinha muito menos imagens para ensinar ao modelo as diferentes classes. No entanto, as melhorias foram notórias: só esta simples alteração aumentou a precisão do modelo para 50%.
Evaluating on the test set...
Found 580 images belonging to 4 classes.
19/19 ━━━━━━━━━━━━━━━━━━━━ 5s 260ms/step - accuracy: 0.6259 - loss: 0.9071
🎯 Final Test Accuracy: 0.51, Test Loss: 1.06
Felizmente, ainda tinha mais imagens que podia utilizar e mais alguns timelapses para extrair frames, mas apenas consegui uma melhoria de 6%. Que desilusão! Afinal, ainda não entendo nada do que estou para aqui a fazer. Isto levou-me a aprender mais umas coisas. Primeiro, aprendi que talvez o modelo estivesse demasiado complexo e com demasiadas camadas (vamos fazer de conta que sei exatamente o que são estas camadas, ok?), e que estas estavam a fazer com que o modelo memorizasse imagens em vez de aprender — “overfitting”. No entanto, ao remover algumas dessas camadas, acabei a prejudicar a capacidade de aprendizagem do modelo, causando “underfitting”. Irra… tira, põe, muda aqui, muda ali, tapa a cabeça, destapa os pés. Após algumas alterações de parâmetros, e em vez de remover layers, acabei a descobrir o “dropout rate”. Verdade seja dita, ainda não entendo muito bem como funciona, mas de forma muito simples, previne que o modelo memorize a informação de treino sem limitar a capacidade de aprendizagem! E boom, 67% de exatidão! Isto quase que é utilizável. Mas aqui reparei e aprendi mais umas coisas: os resultados de treino estavam bastante alinhados com os resultados de validação e, na altura em que o script terminou, o modelo ainda estava a aprender. Estava na altura de aumentar o número de “epochs” até que o “early stop” entrasse em ação. Por outras palavras, “epochs” é o número de “sessões de aprendizagem”, e “early stop” é um mecanismo que para de treinar o modelo quando este deixa de aprender! Aumentei o número de epochs de 30 para 100 e… mas que raio? 52% de exatidão? Mas… mas… como? Lembrem-se de que não fui à universidade! Muitos destes conceitos estão acima do meu conhecimento e estou completamente baralhado! Após algum tempo a coçar a cabeça, a pesquisar no Google e, mais uma vez, a usar LLMs como meus professores de matemática e estatística, aprendi que existe um elemento aleatório que afeta a forma como os dados são distribuídos e os neurónios são criados e destruídos. Cada vez que treinava um modelo, estes eram sempre distribuídos de forma diferente. Para controlar este comportamento, tive que configurar uma “semente” que, basicamente, faz com que o processo de aprendizagem seja sempre o mesmo cada vez que o script corre! Após esta semente configurada, o próximo treino resultou em 66% de exatidão, já mais próximo do valor anterior, mas ainda não suficiente. Quero mais! Será que consigo chegar pelo menos aos 80%? Foi quando um LLM sugeriu utilizar transferência de conhecimento em vez de treinar o modelo completamente do zero, o que basicamente se resume a utilizar um modelo já com algum conhecimento base e adicionar o conhecimento sobre as auroras. Depois de ajustar o script de treino do aeye para o efeito, utilizando o modelo MobileNet como base, o resultado foi um desastre. Assumindo que sei exatamente tudo o que fiz, depois de uns retoques no script, os resultados começaram a parecer melhores. Desta vez… 72%. Embora seja utilizável, ainda estava abaixo da marca que queria de 80%. E se utilizar EfficientNet como modelo base?
84/84 ━━━━━━━━━━━━━━━━━━━━ 37s 442ms/step - accuracy: 0.8083 - loss: 0.4793 - val_accuracy: 0.8576 - val_loss: 0.3609 - learning_rate: 1.0000e-05
Epoch 69/100
84/84 ━━━━━━━━━━━━━━━━━━━━ 38s 450ms/step - accuracy: 0.8275 - loss: 0.4477 - val_accuracy: 0.8487 - val_loss: 0.3701 - learning_rate: 1.0000e-05
28/28 ━━━━━━━━━━━━━━━━━━━━ 8s 296ms/step - accuracy: 0.8493 - loss: 0.3646
🎯 Final Validation Accuracy: 0.86, loss: 0.36
✅ Saved model at models/test_full_3_100epochs_efficientnet.keras
Evaluating on the test set...
Found 892 images belonging to 4 classes.
28/28 ━━━━━━━━━━━━━━━━━━━━ 8s 283ms/step - accuracy: 0.9200 - loss: 0.2367
🎯 Final Test Accuracy: 0.86, Test Loss: 0.34
Finalmente! Exceto que…
Com 86% de exatidão, agora é que isto vai bombar em forte! Tempo de colocar o modelo a correr e observar resultados reais:
Infelizmente, após algumas semanas, outro problema apareceu. O modelo está, de facto, bastante confiável e deteta bem as auroras, mas tal como eu desconfiava, agora o problema é que às vezes pode existir aurora, mas o modelo está incerto se existem nuvens ou não, resultando em 50% de confiança em “aurora com nuvens” e 50% de confiança em “aurora com céu limpo”!
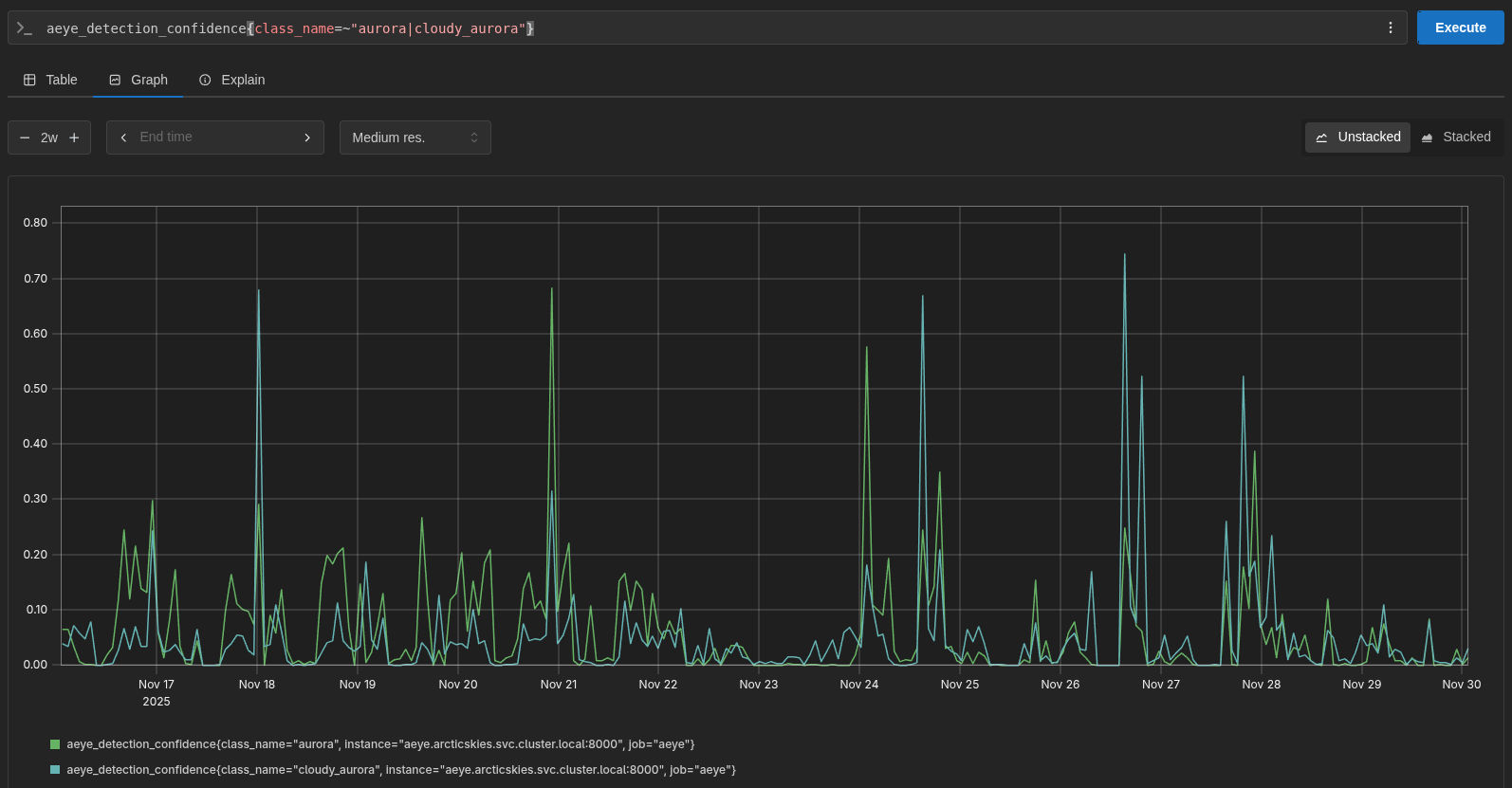
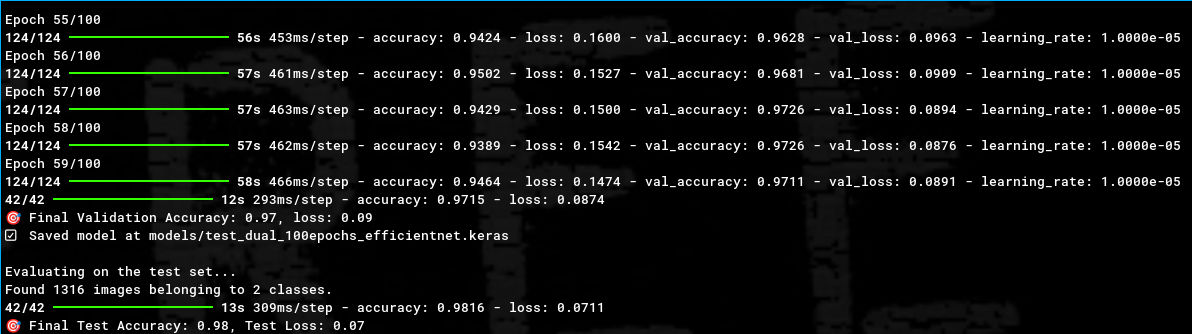
Agora com mais conhecimento, este problema levou-me a questionar o modelo de classificação binária! Talvez o problema não fossem as nuvens, talvez o problema tivesse sido a falta de todos os ajustes que fiz até aqui! Mais imagens, datasets de treino, validação e teste, transferência de conhecimento… Mas, felizmente, um modelo multi-classe pode também ser um modelo binário, basta treiná-lo com duas classes! Reajustei as imagens para representar apenas as duas classes e… que coisa linda, 98% de exatidão no teste final!
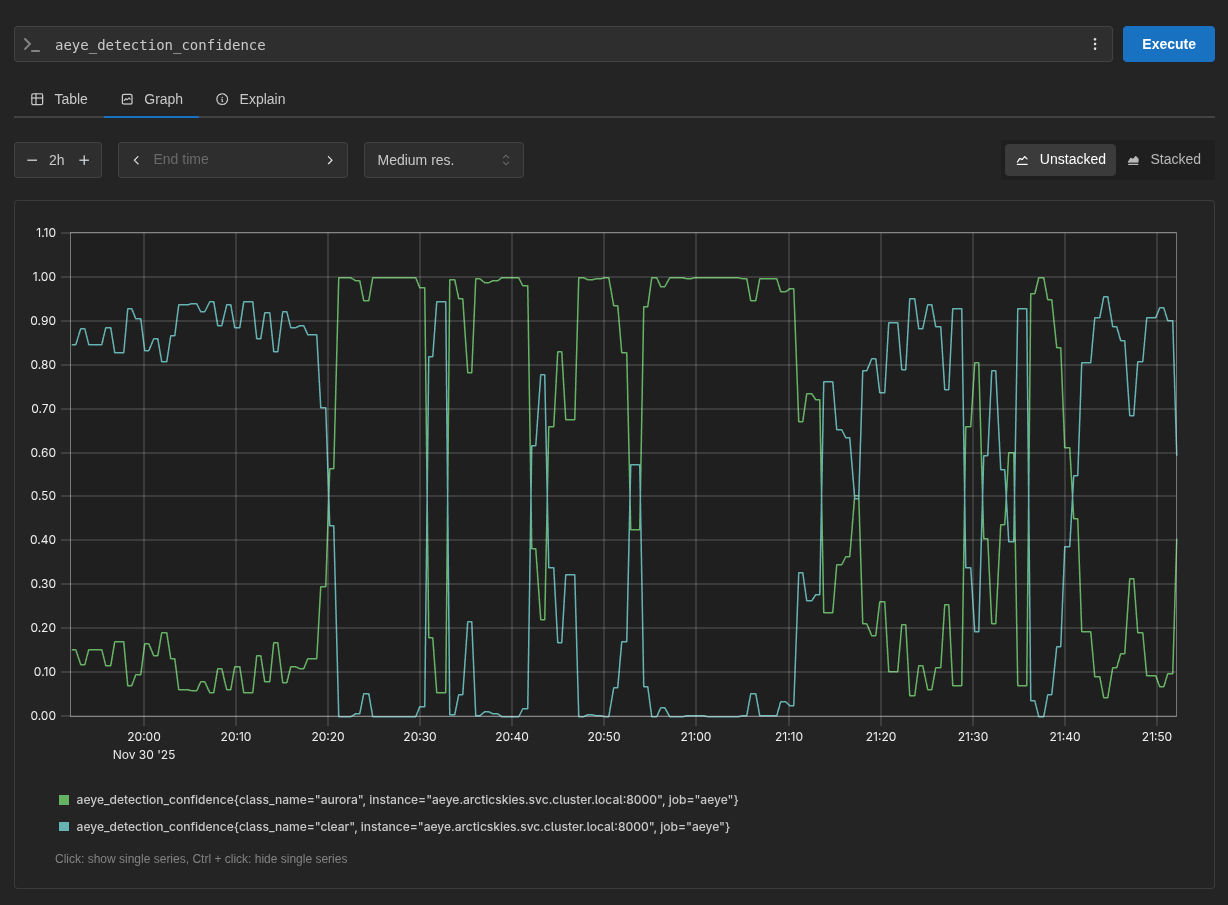
À data de escrita deste artigo, o modelo tem estado a correr e a observar a stream por algumas semanas. E certo, às vezes ainda marca algumas nuvens ou outros artefactos como auroras, mas muito rapidamente volta a corrigir essa decisão poucos frames depois. São raras estas ocasiões e, na maior parte dos casos, está certo, o que me tem ajudado a saber quando há auroras para fazer os vídeos de timelapse!
Só faltam os alertas… mas…
Agora que o modelo está testado e funcional, está na altura de tratar dos alertas. Se fosse só para mim, uns alertas feitos no Grafana IRM serviam perfeitamente. No entanto, quero que qualquer pessoa possa subscrever aos mesmos, seja para os ter nos canais do Discord/Slack/email e poderem ver a stream e observar as auroras boreais quando estão visíveis! Não fosse o meu servidor principal ter morrido e agora estar a meio de mudar a configuração do meu home lab!
